在前两篇([2025-all-in-one-home-server-project---part-1-building-from-the-ground-up|1],[2025-all-in-one-home-server-project---part-2-network|2])中,我们分别搞定了存储架构和网络设计。现在,我们需要一个能将所有数据都安全守护起来的备份策略。
这篇文章,我将完整地讲述我是如何在这台 All-in-One 主机上,搭建并配置 Proxmox Backup Server (PBS),并最终实现一个几乎满足 3-2-1 备份原则的、自给自足的数据保护闭环。
目标
- 达成 3-2-1 备份: 在单机上,尽可能达成“3 份副本,2 种介质,1 份异地/离线”。
- 简化运维: 日常备份要全自动,操作性故障(手滑删 VM、系统更新搞崩了)的恢复要尽可能简单快速。
- 减少写入损耗: 避免每天对存储池产生 TB 级别的巨大写入,保护硬盘寿命。
核心工具:Proxmox Backup Server (PBS)
我之所以最终决定引入 PBS,而不是依赖 vzdump + ZFS dedup,正是因为后者是一个巨大的性能陷阱。vzdump 默认压缩后的备份文件,几乎无法被 ZFS dedup 有效去重,而开启 dedup 带来的性能惩罚和删除旧备份时的巨大问题,是我无法接受的。
NOTE
其实主要是删除的问题,dedup 在 PVE 的备份上面是可以有效的,但是需要很多额外的折腾:
- 最基础的:关闭 backup compression, 然后 zfs datastore 上面可能也最好关掉 comrpession。然后记得确保内存够大,1TB需要5GB内存。
- 麻烦的地方:大概需要在backup后进行一次解压缩,才能真正去重(所以需要先备份到一个地方,解压缩,然后再 copy 到 dedup的那个zfs pool)
- 这个原因是,vzdump 出来的是一个 vma文件,类似一个 tar。这是一个夹杂了 block metadata 的包。即使是把 compresion 关闭了,哪怕是有一点打包执行时候的顺序差别,甚至日期差别,都会导致无法 dedup。
- 其实 PBS 就是在一个没有打包的状态下进行的 dedup。
- 删除惩罚:为了安全地删除一个文件,ZFS 必须为这个文件里面的数百万个数据块中的每一个,都执行一次极其繁重的检查。
- 其实吧,这个就看怎么看待了,PBS里面删除也是很麻烦的(prune 然后再等之后space 被回收),但是人家没有把很麻烦的事情包装的很简单。这里实际上是个哲学问题。只不过,可能在 design 层面,ZFS dedup 没有为“彻底删除一个块“的性能做态度工作,而一般来讲一个 ‘rm’,又是阻塞态的。如果是 PBS 里面,当作一个 async job 来处理,其实就还好了,只不过FS层面估计不方便把这个东西搞成 async 吧,那样用户可能会非常困惑。所以终归,这是一个“错位的需求实现”。
PBS 在应用层面对未压缩的虚拟机数据块进行去重,配合 PBS 和 PVE 之间的良好集成度,基本上就注定了对于普通 homelab 来讲 PBS 几乎就是版本答案了。
PBS 的部署:VM 方案的最终抉择
虽然在 LXC 中运行 PBS 在资源上更高效,但在反复权衡后,我还是选择了更保守、更稳妥的 VM 方案。
如果是 PBS via LXC
如果是 PBS via LXC,可以选择通过TrueNAS 上面的 NFS share 来给 LXC 做 data store的存储。方法是在 LXC 里面添加root之外的一个 mount point。 注意这里不是用的 bind mount (bind mount 需要修改 PBS ct config)。而是用直接在 UI 上面选择 NFS backed storage。 这样 PBS CT 里面会创建一个 EXT4 文件系统,在 NFS 的目录上会看到一个 .raw 文件。个人理解这个就相当于在 dir type storage 上面使用 raw VM image。 如果是 bind mount,就是直接没有 EXT4 这层文件系统了,而是直接访问 NFS 挂载的目录。直觉上是比再包一层 EXT4 要更简洁的。但是事实性能可能恰恰相反。很有可能用上面说的 mount point 的方法,在CT里面的磁盘性能会比自作聪明的用 bind mount 直接 bind NFS dir 上面的效果还要好一些(后者跟在CT 里面使用 NFS 挂载的性质其实差不多)。原因是 PBS 的小文件块很多(应该默认是4MiB大小),然后metadata也存了很多。这么多文件的 raw NFS 性能搞不好还没有用 EXT4 包一层之后快。不过这个我没有测试了,所以也不好说。
PBS in LXC 的一个优点是,data storage 就是一个文件。毕竟就是一个文件,管理起来会比 zvol 灵活不少。
PBS VM 的存储架构
这可能是整个 All-in-One 架构中最“绕”的一环,也是最能体现“螺蛳壳里做道场”精神的地方。
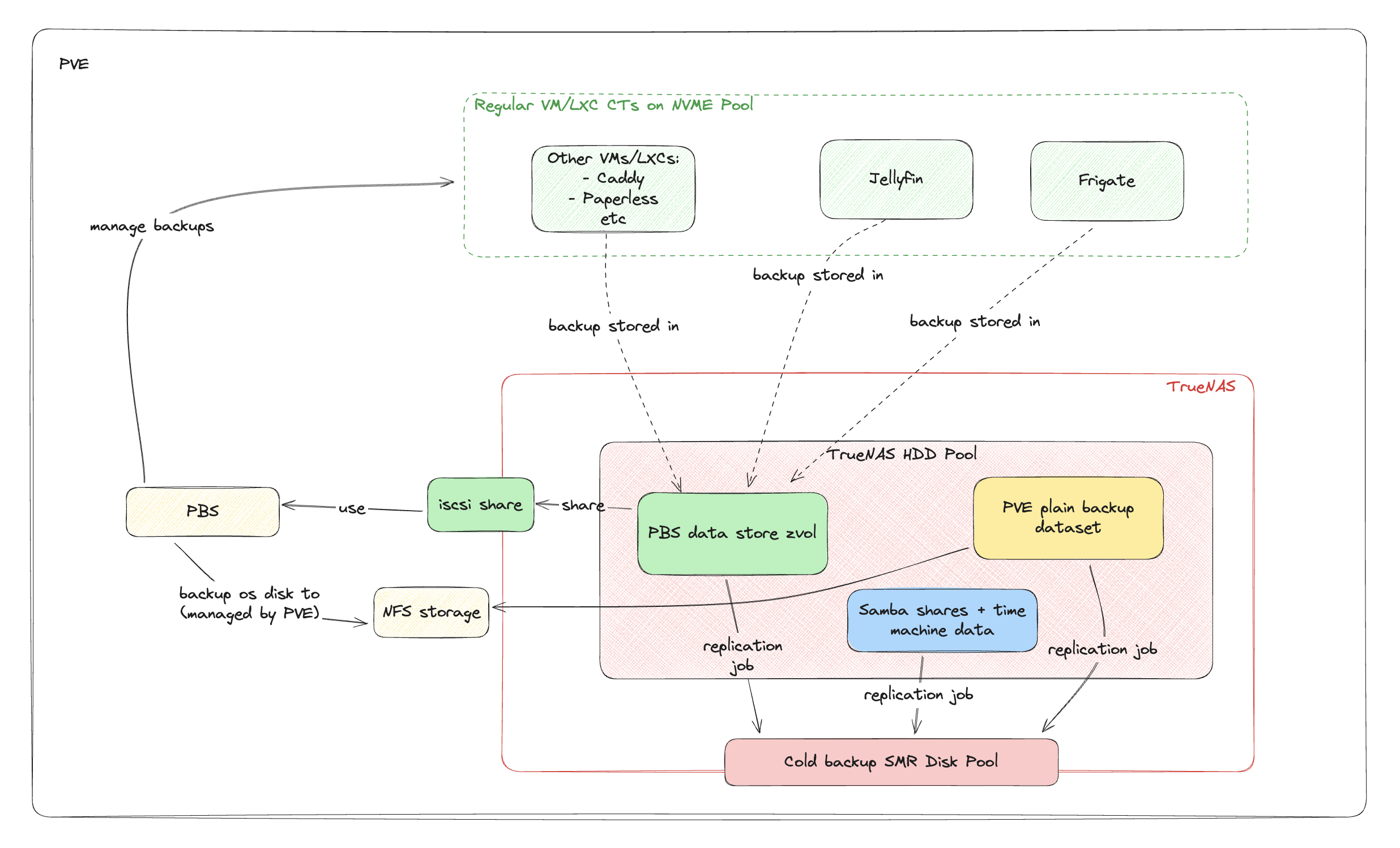
核心策略: TrueNAS 为 PBS 数据仓库提供 ZVOL → 通过 iSCSI 共享 → Proxmox 接收 → 将 iSCSI 磁盘分配给 PBS 虚拟机。
-
为什么要用 iSCSI 而不是 NFS?
- PBS 的数据仓库是一个“块数据库”,而非“文件仓库”。iSCSI 提供的底层块访问,能让 PBS 内部的 ZFS 引擎以最高效率运行,避免了 NFS+ext4 带来的额外抽象层和元数据开销。
-
为什么 PBS 内部还要用 ZFS?
- 这是为了极致的可靠性。虽然底层的 TrueNAS tank 池已经提供了物理层面的数据校验和修复,但在 PBS VM 内部再使用 ZFS,可以增加一层应用层的事务性保障和端到端的数据完整性校验。
- 也是方便之后直接在 VM 里面做 zfs send 等方式迁移。
- 如果 overhead 不大(需要下面的调优),我觉得可以接受。
过程
创建 ZVOL
我登录 TrueNAS VM,在 tank 池中创建了一个 8TB 的 ZVOL,专门给 PBS 用。这里的参数设置非常关键:
- /mnt/tank/critical/backups/pbs: 这是 ZVOL 的路径。
- compression: off: 关掉!因为 PBS 自己会用更高效的 zstd 压缩数据,在 ZFS 这一层再压缩纯属浪费 CPU。
- volblocksize: 128k: 关键的对齐操作。因为 PBS 内部创建的 ZFS datastore,其默认 recordsize 就是 128k。让底层和上层的“积木块”大小一致,可以避免严重的性能惩罚。
- sparse: true: 这样 ZVOL 只会占用实际使用的空间,按需增长。
- secondarycache=none: 这个需要在 Shell 里手动 zfs set secondarycache=none tank/critical/backups/pbs。目的是防止 PBS 的备份数据流污染我宝贵的 L2ARC 缓存,把 SSD 空间完全留给 Immich。
NOTE
这个 ZVOL 的参数是为 PBS 量身定做的。它完全不适合普通的虚拟机(通用 VM 我会用 64k 的 volblocksize 和开启 lz4 压缩)。
配置 iSCSI 共享
在 TrueNAS 的 iSCSI 向导里,我创建了共享:
- name: truenas-pbs
- sharing platform: Modern OS。为什么选这个?我也不知道,反正我用的不是 VMWare,而 Proxmox 9 怎么也算“现代”操作系统吧。
- initiator: 我先把它留空,允许所有 initiator 连接。这样,我就可以先去 PVE 那边,确保能成功发现这个 Target。等一切都配置好之后,再回来把 PVE 的 IQN 填进去,把权限收紧。
TIP
PVE 的 IQN(iSCSI 的全球唯一“身份证号”)存放在 /etc/iscsi/initiatorname.iscsi。强烈建议把这个文件备份一份。未来如果重装 PVE,只需把这个文件恢复回去,所有 iSCSI 连接都能无痛恢复,无需在 TrueNAS 上做任何修改。
Proxmox VE - 添加 iSCSI 存储
回到 PVE,在 数据中心 → 存储 中添加 iSCSI。填入 TrueNAS 的 IP 后,因为我们之前 initiator 留空了,所以 Target 很快就被发现了。
- use LUNs directly: 我在这里勾选了它。我们之前的讨论已经明确,勾选它,意味着这个 LUN 会被“一对一”地直接附加给虚拟机,中间没有 LVM-Thin 层。对于“整个 LUN 只给一台 VM 用”的场景,这能大大简化灾难恢复的流程。
- 用了这个 flag 之后,似乎在 PVE 的 storage 里面,就看不到这个storage 的大小了。
修改之前创建的 PBS 虚拟机
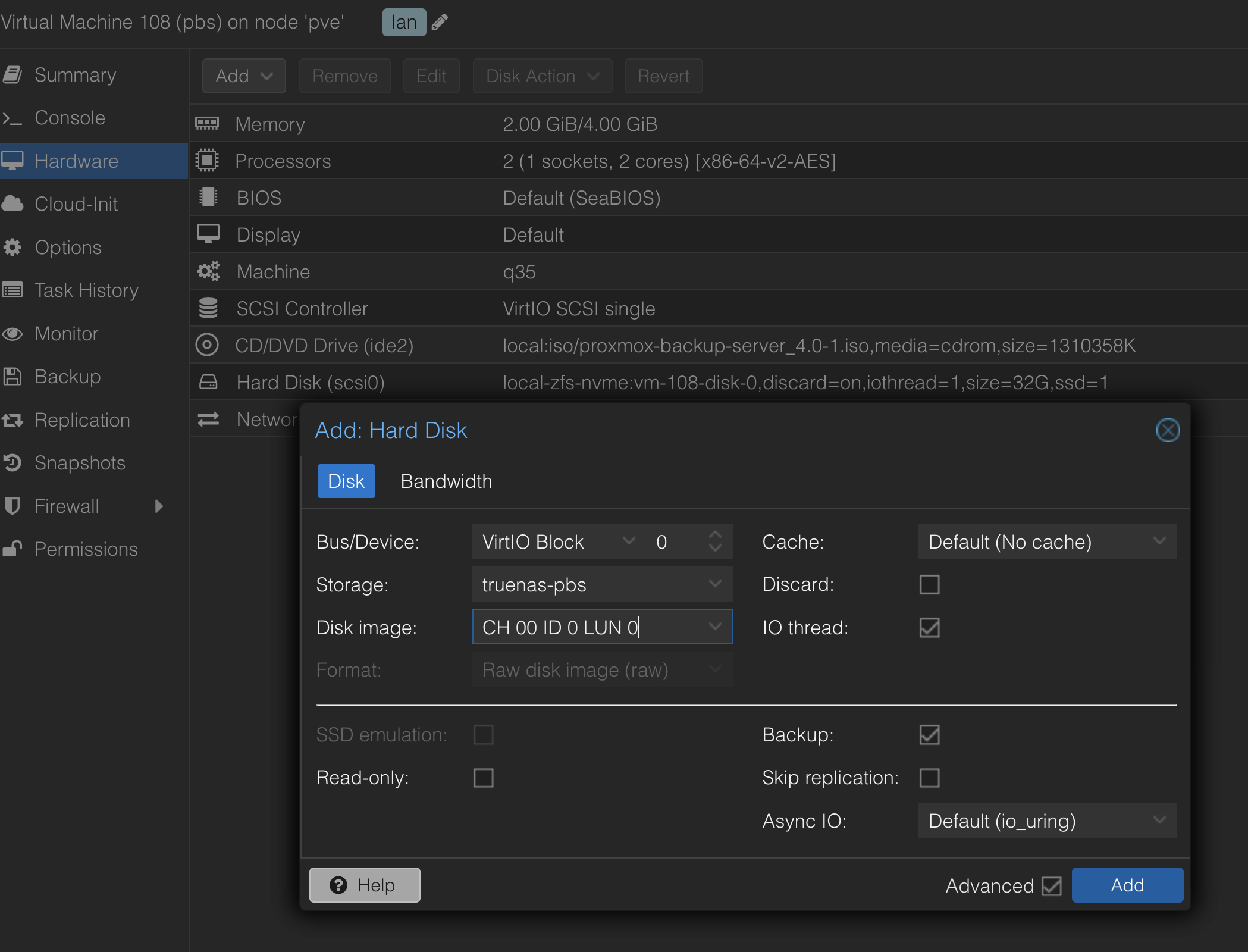
我先用 32GB 的系统盘(在本地 NVMe 池上)安装好了一个基础的 PBS VM。然后关机,准备给它接上“仓库”。
在 VM 的硬件菜单,添加第二块硬盘。存储选择我们刚刚创建的 iSCSI 直连存储。
- 扫描 LUN 的过程确实感觉有点慢,需要点耐心。
- 总线类型我选择了 VirtIO Block,性能理论上比模拟的 SCSI 更好。
NOTE
目前,我的 PBS VM 分配了 2-4GB 内存,数据仓库是一个 8TB 的 ZVOL,实际备份数据量约 1TB,运行状态良好。这个内存使用量也算是一个 data point。虽然很多地方都说使用 ZFS 最小内存是 8GiB。但是我还是想试试看4GB,甚至2GB对于一个家用备份服务器是不是已经够了。
创建 ZFS Datastore in PBS VM
在 PBS 的 Administration → Storage/Disks 中,添加 ZFS,用刚刚给进来的那个 /dev/vda 磁盘。(这里因为我一开始装这个 PBS 的时候,系统盘用的 bus 是 scsi,所以 /dev/vda 是这个 data store 的盘,如果系统盘用的就是 virtio bus, 那大概率 /dev/vda 是系统盘吧,那就应该用/dev/vdb了。)
我选择用 zfs 来格式化它。PBS 自动创建的 ZFS 池,其 recordsize 默认就是 128k,正好与我底层 ZVOL 的 volblocksize 完美对齐。
ZFS 调优:
创建成功后,我登录 PBS 的 Shell,对这个新创建的池 (datastore 默认池名通常就是你起的名字,例如 main-store) 做了两项标准优化:
zfs set atime=off main-store
zfs set xattr=sa main-storePBS 后期处理
运行社区的 Post-Install 脚本,修复一下软件源,顺便干掉烦人的“订阅”警告。 Link: https://community-scripts.github.io/ProxmoxVE/scripts?id=post-pbs-install
apt install qemu-guest-agent 并 systemctl enable --now qemu-guest-agent,这是所有 PVE 虚拟机的基本流程。
PVE 连接 PBS
最后一步,回到 PVE 的 UI,正式告诉 PVE,它现在有了一个PBS备份服务器。
登录 PBS 的 UI,在仪表盘上找到并复制 Fingerprint。
在 PVE 的 数据中心 → 存储 中,添加 → Proxmox Backup Server。
Fingeprint 可以从 PBS 的 UI 里面拿到,至于用户名和密码,homelab 根据自己的舒适程度选择要不要再创建一套 user 吧。
备份链
现在,我们有了 PBS,所有 VM / LXC,除了 PBS 和 TrueNAS,都通过 PBS 进行备份,数据都会进入 TrueNAS 里面。
但我们还需要解决两个特殊问题:PBS 自己怎么备份? TrueNAS 怎么备份?
为 TrueNAS VM 备份 (操作恢复):
- 目的地: local-zfs-staging 池 (我那块古董 M500 SSD)。
- 这里我们首先需要给创建一个 ‘dir’ type 的 storage 在这个 local-zfs-staging 上面。这个 local-zfs-staging 之前是创建成了 zfs storage。然后默认挂载在 /local-zfs-staging 上面。但是这个 storage 默认是不能存 backup 的。我们需要用这个目录再创建一个 dir type storage,然后才能使用这个目录。这里我的 dir type storage name 是 ‘local-zfs-staging-dir’.
- 方式: 每月一次的 vzdump 任务,备份文件只有 4GB 多一点,可以接受。保留过去三个月的
- 理由: 备份目的地必须独立于 TrueNAS 自身。
- 手动:时不时 export 一份 config,然后妥善存好。
为 PBS VM 备份 (操作恢复):
- 目的地: TrueNAS tank 池上的一个专用 NFS 共享 (tank/backups/pve)。
- 方式: 每周一次的 vzdump 任务,并排除了那块 8TB 的数据盘,只备份 32GB 的系统盘。
- 理由: 备份目的地必须独立于 PBS 自身。
为所有其他“客户”VM/LXC 备份:
- 目的地: PBS 数据仓库。
- 方式: 每日一次的、增量永久、去重的高频备份。
冷备份与灾难恢复
集中归档 (Optional) 为了简化冷备份,我们可以设置一个 cron 任务,定期将 PVE local-zfs-staging 上的 TrueNAS 备份文件,rsync 一份到 tank/backups/pve。这样,所有用于灾难恢复的“蓝图”(vzdump 备份和 TrueNAS config)都集中到了 tank 池中。
不过这个必要性不大,毕竟 TrueNAS 自身的灾备就是自己那个 config (当然我也不打算用 TrueNAS 上面太 advanced 的功能,避免因为版本升级带来一些不必要的麻烦)
冷备份流程 我将 4TB 的 SMR 硬盘命名为 cold4。每次更新冷备份,流程是:
- 将 cold4 硬盘插入直连 TrueNAS VM 的热插拔盘位。
- 在 TrueNAS UI 中导入该池。
- 在 TrueNAS UI 中,对包含所有核心数据(PBS 数据仓库ZVOL,vzdump文件,shared 文件等)的数据集,手动运行一次预设好的复制任务 (Replication Task)。
- 完成后,在 UI 中导出该池。
- 导出的时候注意不要删除这个 pool 相关的 configs。默认是会删除的,需要把那个 selection box 取消掉。
- 将硬盘取出,妥善保管。
4TB SMR 盘的特殊 ZFS 设定
recordsize=1m; primarycache=metadata; secondarycache=none; atime=off这些设置确保了在备份时,它能以对 SMR 最友好的大块顺序方式写入,并且不会用冷数据污染我宝贵的 ARC 和 L2ARC 缓存。
灾难恢复 现在,我的 3-2-1 原则“几乎”达成了。我拥有了:
- 3 份副本: 生产数据 (在 NVMe/HDD 上), PBS 备份 (在 HDD 上), 冷备份 (在离线 HDD 上)。
- Except PBS system disk, TrueNAS system disk, Immich bulk media data disk.
- 2 种介质: NVMe SSD 和 HDD。
- 除了 Immich bulk media data disk.
- 1 份离线: cold4 冷备份盘。
(当然,“异地”这一环取决于我把这块盘放在哪里…)
这份冷备份,包含了从零重建整个系统所需的一切:TrueNAS 和 PBS 的 vzdump 备份,以及 PBS 的完整数据仓库。恢复过程虽然会很“折腾”,但至少我们有了一张清晰的路线图。
一些小小的感悟
TrueNAS 在 All-in-One 中的意义: 理论上,PVE 自己就能搞定 ZFS。但对于我这种记不住命令行的懒人来说,TrueNAS 提供的 UI,特别是在管理快照、复制任务和云同步方面,其价值是很难替代的。它让复杂的 ZFS 运维变得(相对)简单直观。
UI vs. CLI: 开车的老司机没必要嘲笑不会造发动机的人。TrueNAS 的 UI 好用,能让不那么专业的人,用更短的时间完成 80% 专业的工作,这就是它的价值。
后记
最终还是有些后悔用iscsi 来做 PBS 的 data store 的磁盘。因为 zvol 的后端限制多一些。比如,没有办法在之后使用 cloud sync 或者 alist 之类的工具把数据同步到云端备份。
最后的存储和备份安排:
TrueNAS: tank pool
- vmdisks
- pve → server as vm disks for PVE, will use the secondary cache.
- backups
- pve → plain backup from pve and pbsbox vmdisk
- pbs → plain dir to be NFS mounted by PBS VM
- shared
- smb share to home lan.
- media → snapshot every 1 week, keep 2 weeks
- jellyfin
- smb share to Jellyfin LXC
- mount in
filebrowserin TrueNAS app
- qbittorrent → smb share to qbittorrent LXC
- smb share to Jellyfin LXC
- mount in
filebrowserin TrueNAS app
- jellyfin
- nvr → snapshot every 1 week, keep 2 weeks
- frigate
TrueNAS config for tank/backups/pbs
- recordsize=1M (inherited from tank/backups)
- secondarycache=none (inherited from tank/backups)
- NFS share:
map_root_usertoroot,map_root_grouptowheel- This is equal to set the no_root_squash for the NFS on TrueNAS
- This is *NEEDED othewise you will see
EPERM: Operation not permittederror- I’ve tried:
- map all user to a specific user on TrueNAS
- set the permission of the NFS dir on trueNAS to 777
- use chown on PBS VM → error:
chown: changing ownership of '/mnt/datastore': Operation not permitted(pbs 用的是 backup:backup UiD:GID)- TrueNAS Scale 上面的 backup user, backup group 的 ID 是一样的,倒也还好吧。
- 没办法,这个no_squash是必须的。要不然就是没法用。
- I’ve tried:
In PBS VM:
/etc/fstab192.168.1.100:/mnt/tank/backups/pbs /mnt/datastore nfs defaults,hard,async,_netdev,vers=4.2 0 0
- Change default editor to VIM [change-the-default-editor-to-use-in-linux-terminal]
systemctl edit proxmox-backup.service:
[Unit]
Requires=mnt-datastore.mount
After=mnt-datastore.mount- Add /mnt/datastore to be a PBS datastore.
- 之后可以选择创建 namespace,然后创建用户,给 PVE 用,让这个 PVE 只能访问这个 datastore 。
- Connect PVE and PBS,这里需要 Fingerprint, datastore 的名字,还可以添加一个 namespace.
TIP
可以临时把 PBS NFS share 的 sync 关掉。这个非常影响速度,比 iscsi-ZVOL 使用 sync 的时候性能影响更大,应该是因为 NFS 还是对元数据修改不友好。
Commands to get the Disk Status
In TrueNAS:
sudo smartctl -i -n standby /dev/<disk_name>
# Example sudo smartctl -i -n standby /dev/sdf
# If the device is in 'standby' mode, it will not wake up the device.
# if you want to manually push your disk to standby (after pool export)
sudo hdparm -y /dev/<disk_name>NOTE
In TrueNAS, there is a ‘standby’ and a ‘advanced power management’ option in the ‘disk’ list → edit menu.