Paperless 是一个自托管的开源文档管理WebApp。主要就是针对越来越多的纸质文档以及PDF文档,做一个有效的管理。因为集成了OCR,外加AI(sort of)辅助,尽量完成文档归类整理的自动化。这里我们简单介绍一下Paperless,并讲一下如何通过 Docker 部署。
Paperless 简介
这应该已经是很多人共同的感受了,现在的生活中,文档实在是太多了。各种的水电费账单收据邮件通知传单合同疫苗证签证驾照房子车子保单记录复印件Biopage申请文档Dispute退税文档T1T4,成功的把本就一地鸡毛的生活搞的更加的七零八落。然而我们自己都知道,虽然平时不是很常用,但是一到用的时候,很多文档的重要性就显现出来了。这个时候如果没有好的文档管理,难免手忙脚乱,甚至有时文件就丢了。
然后说起文档管理,很多人第一反应就是,文件夹。然而这种单一的树形结构肯定是无法满足现代的需求的。Tag/Label这现在已经是metadata管理的基本操作了。也许double link这种对于通常来说主题非常明确的PDF文档来说没有必要,但是tag和label这一类的已经是必不可少了。然而现在看看Google Drive,以及本地的一层一层的文件夹,文档的整理显然不是个简单的事情,时间一长,干脆就弃疗了。
NOTE
🙊 很难理解为什么Google Drive到现在了还不支持自定义Tag/Label。个人盲猜可能因为很多企业用户实际上也不需要onboard tag/label这种文档管理方式。如果公司是基于文档来运营、管理的,那么文档的层级理应也是跟公司部门层级对应的,所以单一的树形结构反而是最好用的。当然,我们知道网形结构是树形结构的升级版,不过对应于这种网形结构组织形式的运营实体,其实更接近于DAO的理念了吧。跟现在的公司层层负责的结构天然不搭。
Paperless的独到之处就是提供了一个PDF文档的管理方案。注意这里主要是PDF文档。PDF类型的文档实际上是有一些特点的:
- 大多PDF通常来说是 Immutable的。比如合同文件,Invoice,收据,账单,等等。
这类文档天然跟“策划“,“design“,“runbook“,internal tech documentation,snippets和personal notes有很大的不同。Immutable 注定了这个文档涉及的topics是几乎不会变化的。如果一个文档管理系统的分类方式是相对固定的,那么对于一个PDF文档的归类,就应该几乎是完全静态的,或者说是极少需要更新的。也就是说其Index基本上是静态的。而Frequently mutable的文档天然就不好index,因为其涉及的Topics很多时候都是随时发生变化的。而原本的文件夹管理方式,至少还是采用了所有index方式里面,最少经常变化的方式了,毕竟 reorg 还是相对少发生的。
- 大多PDF文档的主题是相对固定且有明确界限的。也就是说用多个label基本可以完成一个PDF里面内容的概括。
这就表明,一个相对完善的tag/label系统,就可以建立起一个足够好用的index系统,允许用户从各个角度,快速找到一个文档。比如我即可以通过“收据“,也可以通过“财产“两条路线找到家里修漏水管的维修收据。
这里推荐官方的Screenshots Gallery,做的很好,cover了很多Paperless的优势所在,强烈推荐感兴趣的小伙伴去看一看是不是自己的菜。
当然除了Tag之外,paperless也提供很多其他对于PDF文档常见的Metadata,比如文档类型(收据?合同?确认函?),correspondents (相当于这个文档如果是涉及双方,其中另一方是谁?)
Paperless作为开源application,已经发展了很多年了,现在不仅稳定性已经相当的不错,在OCR和AI上面的集成也达到了相当可用的状态。Paperless会学习用户添加label的习惯,然后结合OCR,会尝试自动给新添加的文档添加Label。结合Paperless已经有的import途径(包括webUI,email,consume directory等),在合理的配置之后,也许是可以达成靠谱的,自动归类自动管理的。
同时,Paperless还有一个手机端的App,不仅可以查看文档,还可以快速的通过手机摄像头添加新的文档。如果手上有纸质的文档,可以立刻通过手机把文档导入Paperless。这个手机端App的完成度已经相当之高。Google Play上面已经有10K+的装机量,这个在开源 Self-hosted application里面可以说是非常牛了。
部署
对于家庭使用,个人认为数据库后端用 SQLite应该就够了 ,不需要使用MySQL或者PostreSQL。官方提供了非常好的Docker compose 模版,选择你想要用的DB后端,然后基本上只需要少许修改就可以了。
个人比较推荐的 SQLite + Tika
注意在官方的 docker-compose folder 下面,还有两个文件 docker-compose.env 和 .env 。这两个文件也是需要的。然后需要做一些修改。
Docker-compose.env:
- 添加你的public URL
PAPERLESS_URL=https://paperless.example.com - 修改
PAPERLESS_SECRET_KEY的值,搞个UUID上去就行PAPERLESS_SECRET_KEY=change-me - 改时区
PAPERLESS_TIME_ZONE=America/Los_Angeles. - 看需求改默认OCR语言:
PAPERLESS_OCR_LANGUAGE=eng - 对于有自己的反代的人,这里需要特别注意。官方的docker-compose.env里面是没有指定下面这两个 environment variable的。但是大概率你需要修改。假定外网的域名是paperless.example.com,内网DNS上面的域名是paperless.example.local。然后内网应该需要unblock access by LAN IP。这样能保证Reverse proxy在内网的链路是畅通的。
PAPERLESS_ALLOWED_HOSTS=paperless.example.com,paperless.example.local,localhost,127.0.0.1,<LAN IP>
PAPERLESS_CORS_ALLOWED_HOSTS=https://paperless.example.com,http://paperless.example.local,http://<LAN IP>,http://127.0.0.1
- OCR语言是情况而定
PAPERLESS_OCR_LANGUAGES=tur ces chi-sim chi-tra USERMAP_UID=1000+ USERMAP_GID=1000这个是应该使用的,但是需要确认一下你的consume/export 的 volume 或者 binding (多数情况下这两个估计是binding? 要不然怎么import/export?) 在 host 上面的目录是有相应的权限的。如果是SAMBA/NFS mount directory,很可能需要在/etc/fstab里面做一些调整。
之后只需要正常的设定 Reverse Proxy 就可以了。
Email 配置
Paperless 一个非常重要的功能就是可以登陆配置好的邮箱,读取其中的 PDF 文件,自动添加到 Paperless 里面。
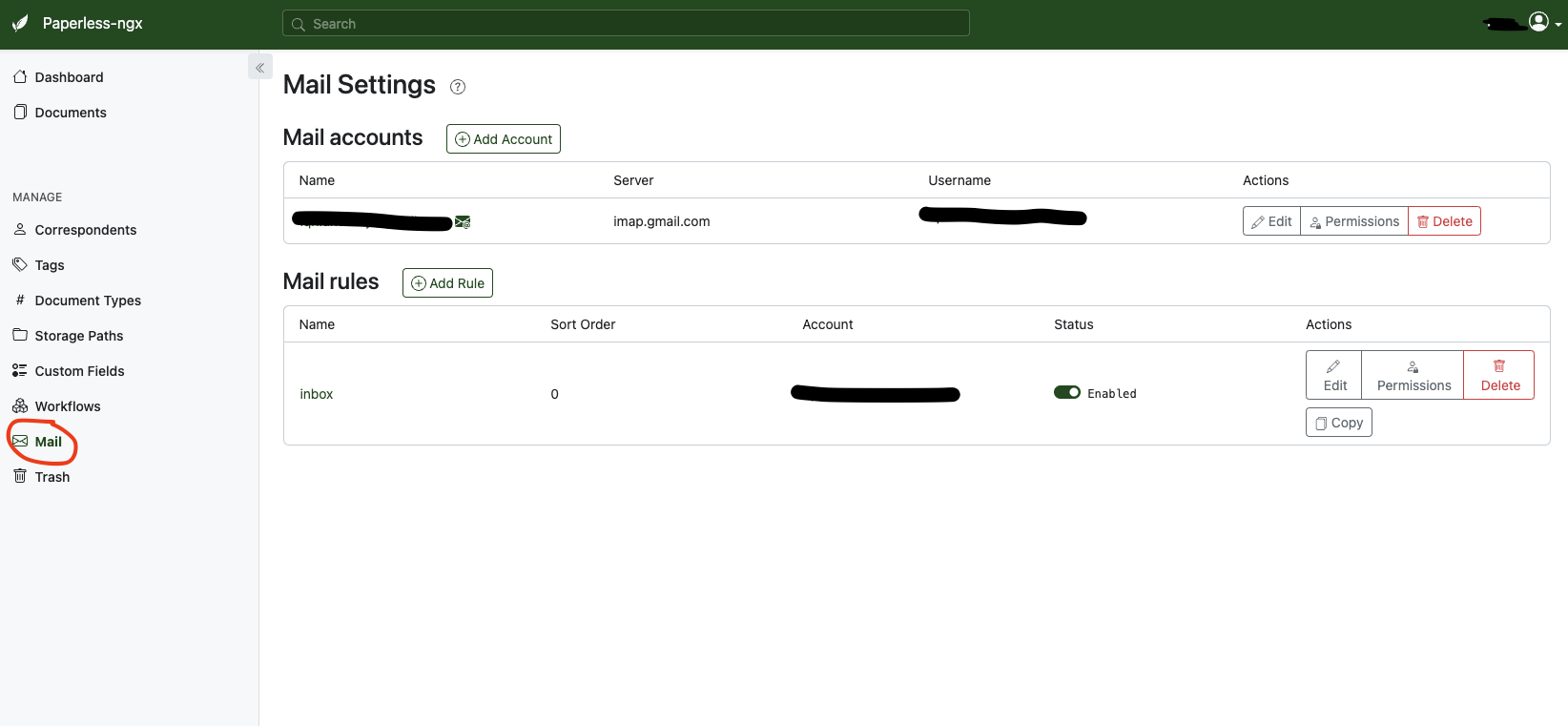
首先需要先配置好一个 Mail Account. 然后再配置相应的 Rules 来自动处理邮箱里的邮件。
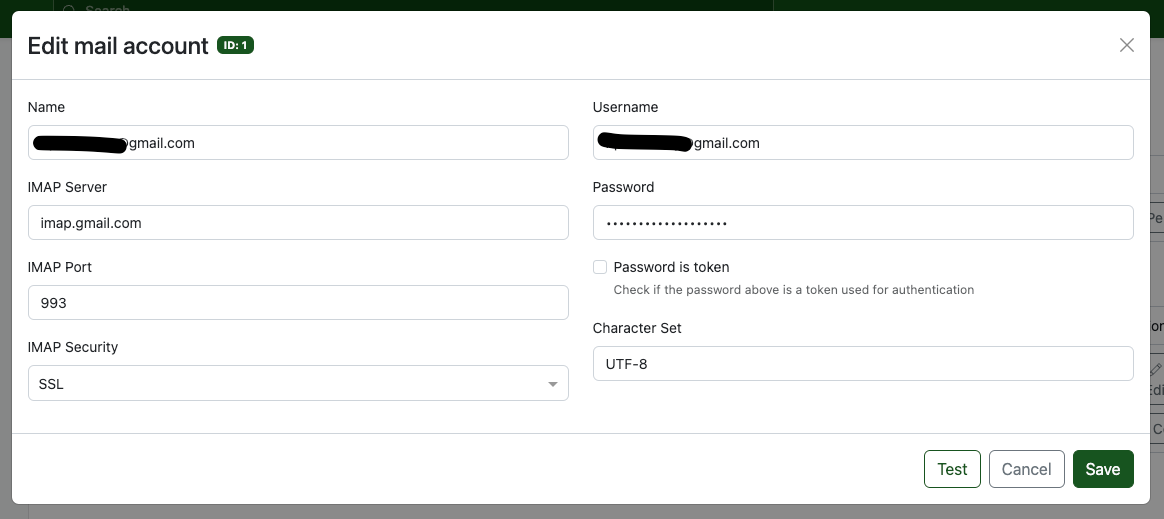
如果是Gmail的话,这里跟之前的文章一样,需要从Google Accounts 里面拿到 Application Password。注意password这里肯定是不可以使用我们平时用来登录 Gmail的密码,必须是单独生成的 Application Password。用 ‘Test’ Button 可以方便的进行测试。还可以配合 paperless container 的 log 来具体分析error message。Application password 可以参考:[set-up-smtp-for-ghost-to-unlock-member-registration-and-login]
一个简单的 Rule:检查过去14天之内的,在 Gmail Inbox 里面的,有 Attachments 的邮件,ingress 其中的附件。然后对于处理过的邮件,添加 paperless'ed tag。处理过的邮件就不再处理了。
移动端
笔者使用Android,所以都是在Playstore上面找。Playstore上面搜索Paperless,会找到两个顶着Paperless图标的App。一个叫Paperless (developed by Johann Bauer),一个叫Paperless Mobile (developed by Anto Stubenbord)。此时此刻(2024-01-06)笔者认为后者好用一些。可以直接调用摄像头,直接拍摄,直接导入文档库。F-Droid上面应该也是有这个 Paperless Mobile的。
后记
其实无论采用什么样的文档管理方案,目前来看,还是需要不少的手动操作的。不过联想到ChatGPT强大语义理解能力,也许很快,这一类的工作就都会由AI来处理了。到那时,也许这些Metadata的管理,就又显得画蛇添足了。
常见问题
- OCR乱码问题
- 好好的PDF,导入之后就成乱码了。这还不是中文的问题。很多时候英文的税单,也会出现乱码。
- 解决方法是:在 Configuration 里面的 OCR Settings → Output Type 改成
pdf。默认的是pdfa。而pdfa是pdf的一个子集。改完再导入就好了。终于可以愉快的使用了。
- 有签名的文档被拒绝导入
- 添加这个 Env Var 到 docker-compose 即可:
PAPERLESS_OCR_USER_ARGS: '{"invalidate_digital_signatures": true}' - 这个应该是OCR的时候会无效化数字签名。但是Paperless 是会保存原始版本的,所以应该也不会真的有什么问题。
- 添加这个 Env Var 到 docker-compose 即可: