之前为了方便迁移,Docker Compose部署的Application都尽量采用了 Volume 而不是 Binding的方式处理persistent storage。以为Portainer上面有UI可以方便的迁移Volume。谁知Portainer上面的Stack Migration并不会一并Copy Volume到新的主机。合着似乎只是把Docker compose的内容copy到新主机上面然后部署运行。不过既然用了Volume,那好歹也要用正确的方法迁移文件,而不是直接copy paste。于是就有了一篇日志。(Portainer太让人失望了。)
Basic
这里用的例子是 Jellyfin。因为之前在一台主机上面部署了GPU,于是想着先把Jellyfin硬解以及HDR的问题解决了。GPU直通详见: [proxmox-74-gpu-passthrough]。 首先,在原主机上Jellyfin的部署如下 (stack name: jellyfin):
version: "3"
volumes:
jellyfin_config:
name: jellyfin_config
media:
external: true
services:
jellyfin:
image: nyanmisaka/jellyfin:230305-amd64
container_name: jellyfin
environment:
- PUID=1000
- PGID=1000
- TZ=America/Vancouver
volumes:
- jellyfin_config:/config
- media:/mnt/media
ports:
- 8096:8096
# - 8920:8920 #optional, for https
#- 7359:7359/udp #optional, local discovery
#- 1900:1900/udp #optional, DLNA
restart: unless-stopped
tty: true其中 Volume: media 实际上是一个 Samba share,存实际的媒体文件。而volume: jellyfin_config是Jellyfin的配置文件以及各种metadata。这里需要迁移的就是这个jellyfin_config volume。这里 jellyfin_config 实际是给了一个特定的 name 的。这导致这个volume的全名就是 jellyfin_config 而不是 jellyfin_jellyfin_config (aka <stack_name>_<volumes_key_in_yaml>)。通常这个应该是需要在多个service或者app之间共享volume才需要的。不过这里已经是这样了,就不去纠结了。
sudo docker volume ls
# Should show "jellyfin_config" volume
sudo docker volume inspect jellyfin_config
# Details of the volume, including:
# * Mountpoint: the absolute path of the volume on the docker host machine:
# * /var/lib/docker/volumes/jellyfin_config/_data
# * Labels: should contains the label: '"com.docker.compose.project": "jellyfin"'单纯使用SCP迁移Volume可能遇到的问题是Permission可能会乱掉,新的文件的ownership以及ACL都有可能因为SCP而被破坏,这在目标机上面重新部署Docker container的时候可能造成很多麻烦。目前来讲比较干净又简单的方式是使用 rsync。但是因docker volume所在的位置一般都是 /var/lib/docker/volumes/,通常需要root权限,rsync 远程直接从Ubuntu上面搞还真不一定成。这个时候就会想念Debian上面可以打开SSH的Root用户。这里采用的方法是 busybox 。Docker官方的方法太过Heavy,直接用Ubuntu image,其实用busybox就足够了。
# 假设把backup.tar放在$HOME
sudo docker run --rm \
-v jellyfin_config:/volume-backup-source \
-v $HOME:/volume-backup-target \
busybox sh -c \
'cd /volume-backup-source && tar cf /volume-backup-target/backup.tar . '
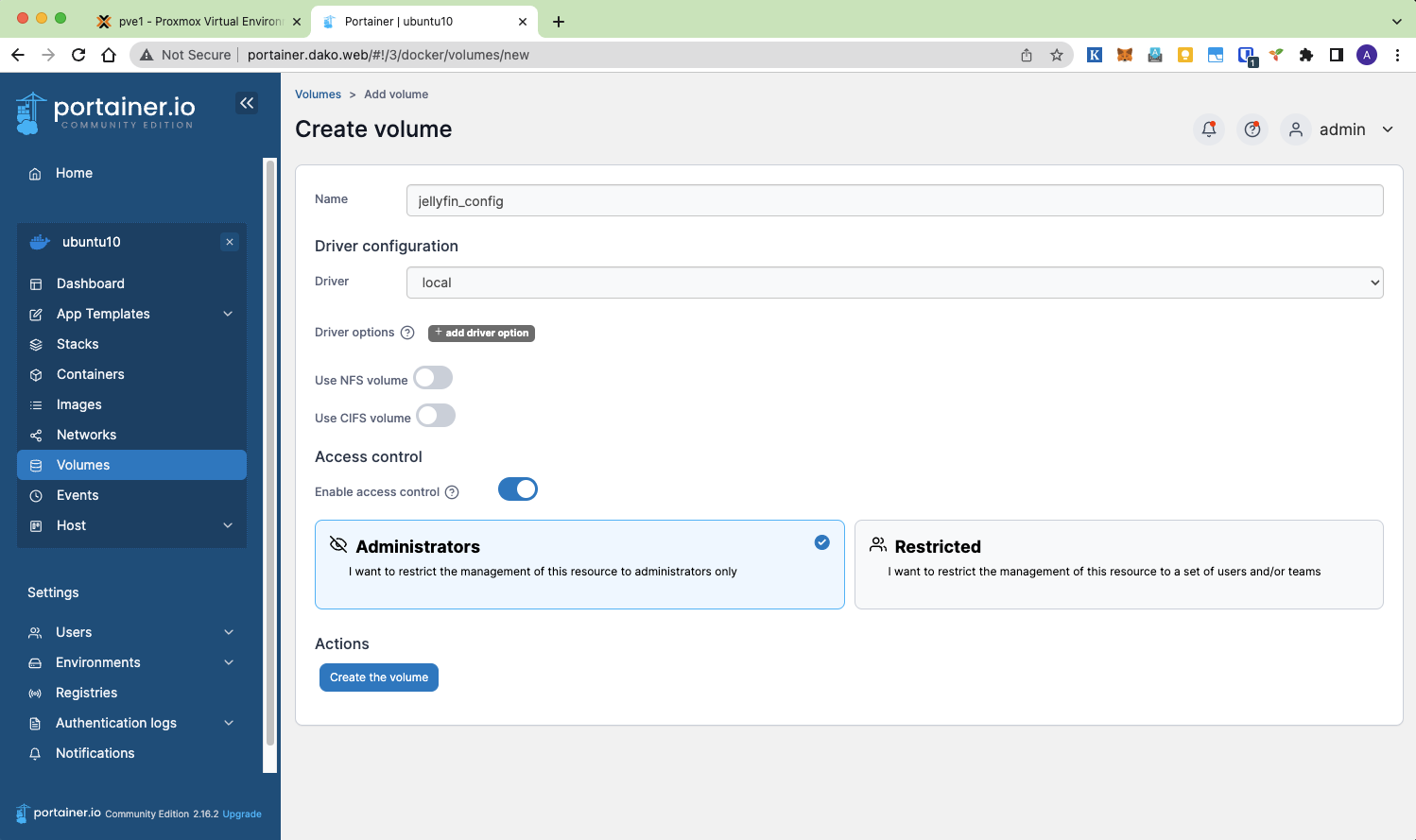
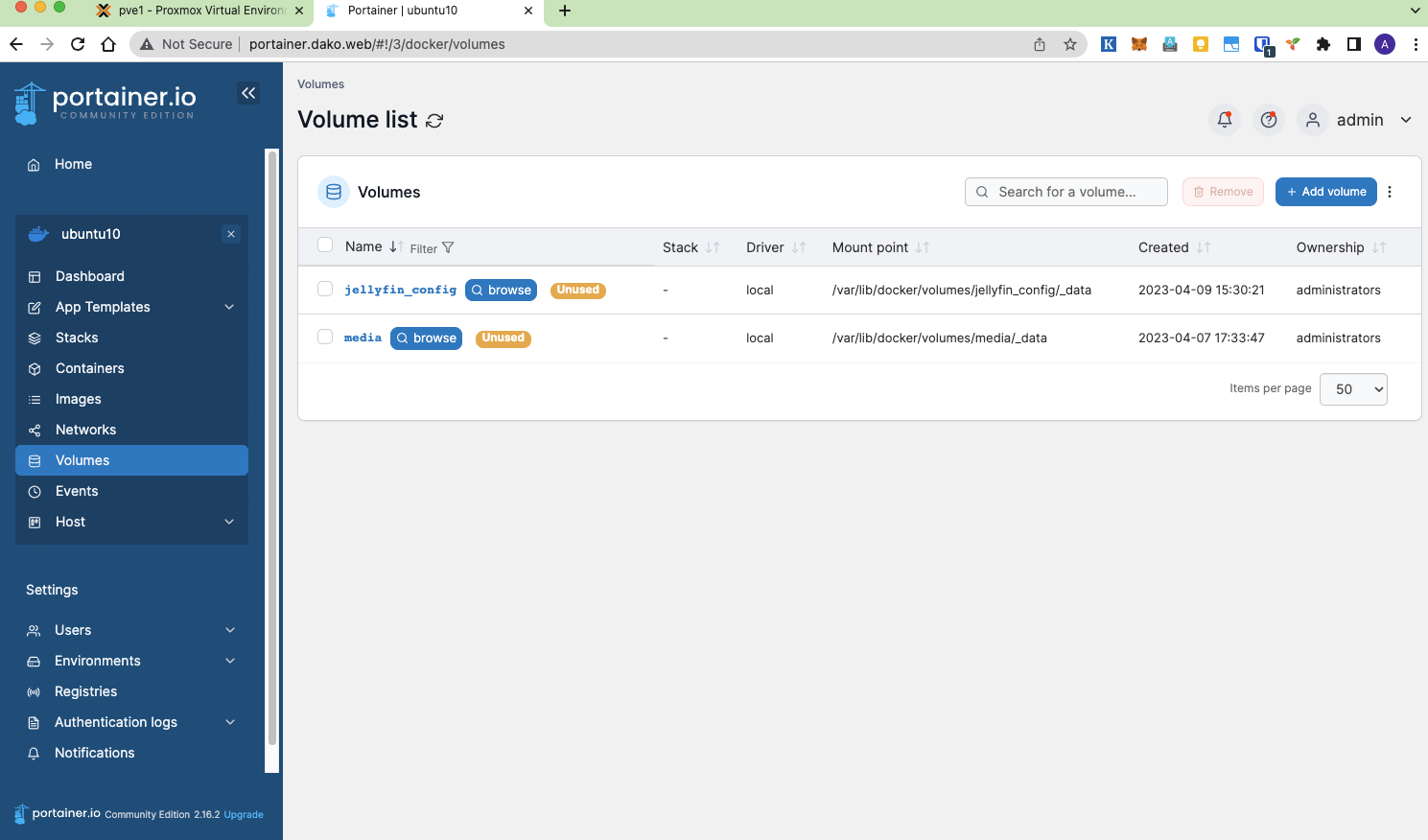
# Result: A 'backup.tar' file in $HOME之后SCP到目标机。目标机上面需要创建这个Volume。因为之前一直用的Portainer,所以这里依旧用Portainer来创建。也可以用 docker create volume <volume_full_name> 来创建。因为Jellyfin用了SAMBA share挂载Media文件,所以这里也需要创建相应的Media volume。
最后用 busybox container 再把 backup.tar 展开到目标 Volume 上面。
# Assume 'backup.tar' is at $HOME
sudo docker run \
--rm \
-v jellyfin_config:/volume-backup-target \
-v $HOME:/volume-backup-source \
busybox \
sh -c 'cd /volume-backup-target && tar xf /volume-backup-source/backup.tar .'在新的server上面,还有几个设置需要搞定,是关于Nvidia Docker的支持的。详见“关于Nvidia的Docker支持”章节
之后再在Jellyfin上面把 Jellyfin stack 跑起来就可以了。这次可以添加GPU加速了。(这里假定服务器是 Ubuntu,所以UID GID用的是1000。如果是Debian,一般默认的GID应该是100)
version: "3"
volumes:
jellyfin_config:
name: jellyfin_config
media:
external: true
services:
jellyfin:
image: nyanmisaka/jellyfin:230305-amd64
container_name: jellyfin
environment:
- PUID=1000
- PGID=1000
- TZ=America/Vancouver
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=all
volumes:
- jellyfin_config:/config
- media:/mnt/media:ro
ports:
- 8096:8096
# - 8920:8920 #optional, for https
#- 7359:7359/udp #optional, local discovery
#- 1900:1900/udp #optional, DLNA
restart: unless-stopped
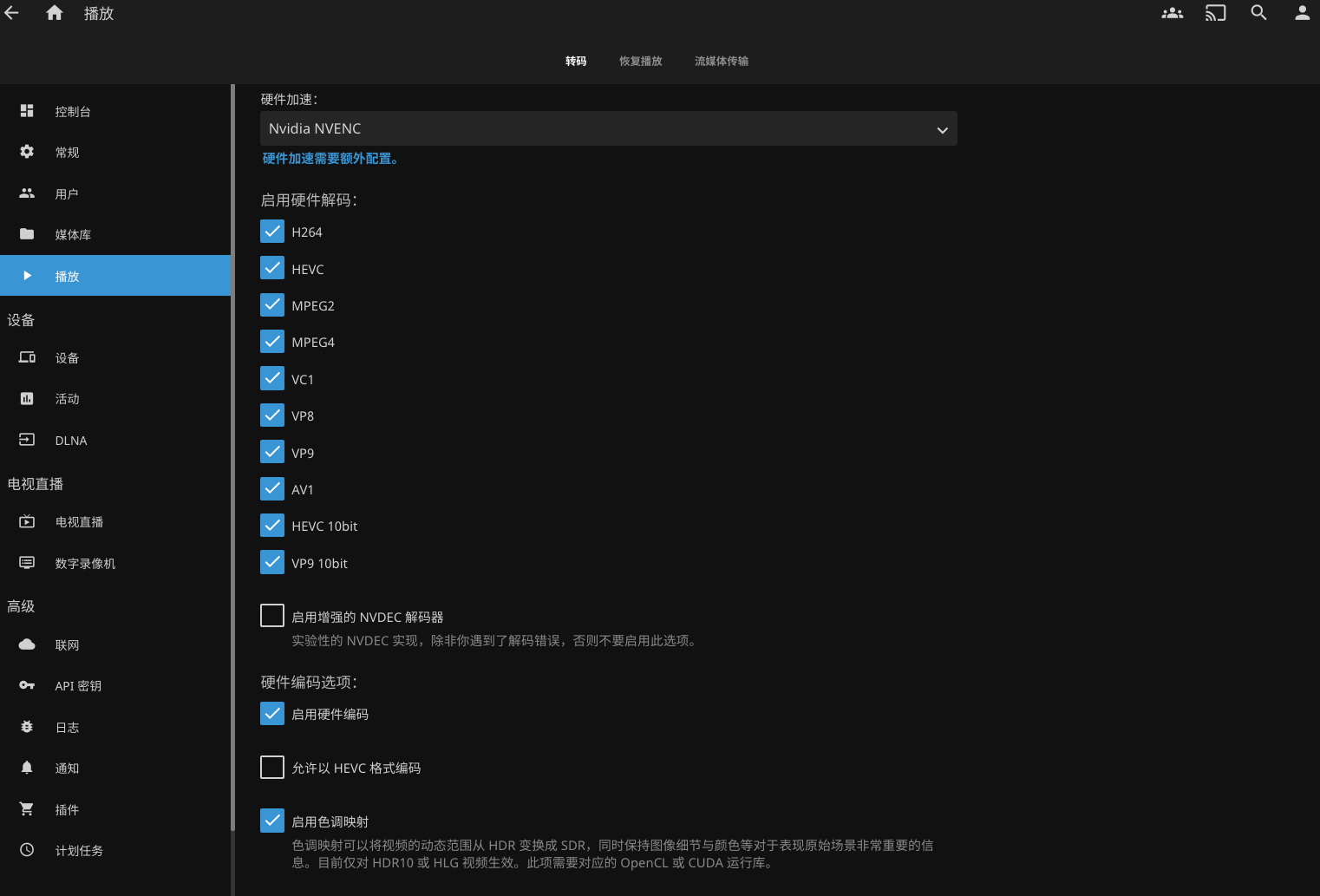
tty: true最后的最后,要去Jellyfin的控制台里面打开硬件加速。
关于Nvidia的Docker支持
目前最方面的做法是Nvidia官方提供的文档
# Add Nvidia Source
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/experimental/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# Update
sudo apt-get update
# Install
sudo apt-get install -y nvidia-container-toolkit
# Config and restart
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
# Test
# Only works for ubuntu22.04, tested at 2023-04-08. Might not work now.
# Need to update the image tag accordingly.
# Ref: https://hub.docker.com/r/nvidia/cuda/tags
sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:12.1.0-base-ubuntu20.04 nvidia-smi不过上面这个测试其实也不一定非常准确(必要不充分条件),在 [proxmox-74-gpu-passthrough] 里面我提到了,这个nvidia-smi就算正确输出了内容,也不保证GPU确实就能用。
- 把当前用户添加进 video group
# 把当前用户添加进 video group
# 因为一般 Jellyfin docker 都是用 UID GID 跑的。
# 一般1000就是第一个用户,一般就是 $USER 对应的用户。
$ sudo usermod -aG video $USER- 更新动态链接 (这一步应该是在 stack 上面已经加了 Nvidia runtime 和 deploy gpu resources,并且部署成功之后)
$ sudo docker exec -it jellyfin ldconfig
$ sudo systemctl restart docker- 最后测试一下 Jellyfin 里面能不能跑 Nvidia-smi
$ sudo docker exec -it jellyfin nvidia-smi串流限制的破解
默认情况下,3090最多只能同时进行3个串流。在Jellyfin上面就相当于,最多只能有3个视频正在串流播放。第四个播放的时候就会发生错误。
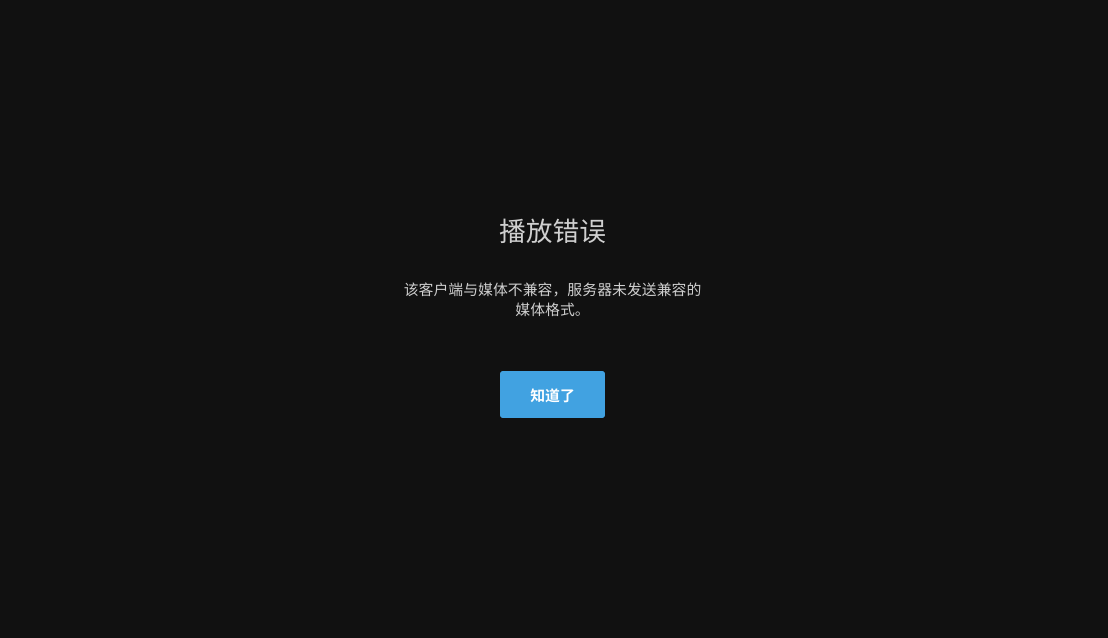
这时就要用到这个神奇的Repo:https://github.com/keylase/nvidia-patch
但是如果要应用在docker app上面,需要对docker file进行修改。这部分以后有时间在做吧。所以目前来说,还不能说算是彻底解决了串流的问题吧。
TIP
更新:
经过验证,在docker host上面直接apply nvidia-patch后,对于Container里面使用NVEC解码也是有效的。所以直接在Host上面运行一次就可以了,不需要考虑修改 Dockerfile 了。