年初时候重新开始折腾服务器,确定了用Proxmox做主机,TrueNAS Scale 存Data的方式,构建整个服务器的架构。又因为心水ZFS mirror几乎“免费“的高可用能力,义无反顾的又一次上了ZFS车。但是因为ZFS的写入放大,以及有时表现出来的不稳定的性能,心里总是不踏实。看了众多的资料之后,决定还是趁着refactor的机会,自己做一次测试,看看问题究竟有多夸张。
背景信息 | Context
Proxmox和TrueNAS社区都是非常不建议用消费级的SSD的,而对于HDD,因为ZFS基本上会让硬盘保持一直运行的状态,所以最好也是企业级的硬盘。可以说,即使用Proxmox+TrueNAS的初衷只是一个小作坊级别的Server,但是因为workload的特性跟一个正常Server不会有什么区别,所以总还是上企业级好一些。Proxmox对于消费级SSD的抵制,实际上更甚于TrueNAS对于ECC的抵制。
但是消费级SSD究竟能有多糟糕,对于小作坊的场景真就不能用吗?网上的信息林林总总,总归跟自己的情况不一样,有时也是婆说婆有理公说公有理,很难做出准确的判断。
一个比较确切的测试是来自Proxmox,关于ZFS + NVME性能的一个文档
重要的部分截取如下:
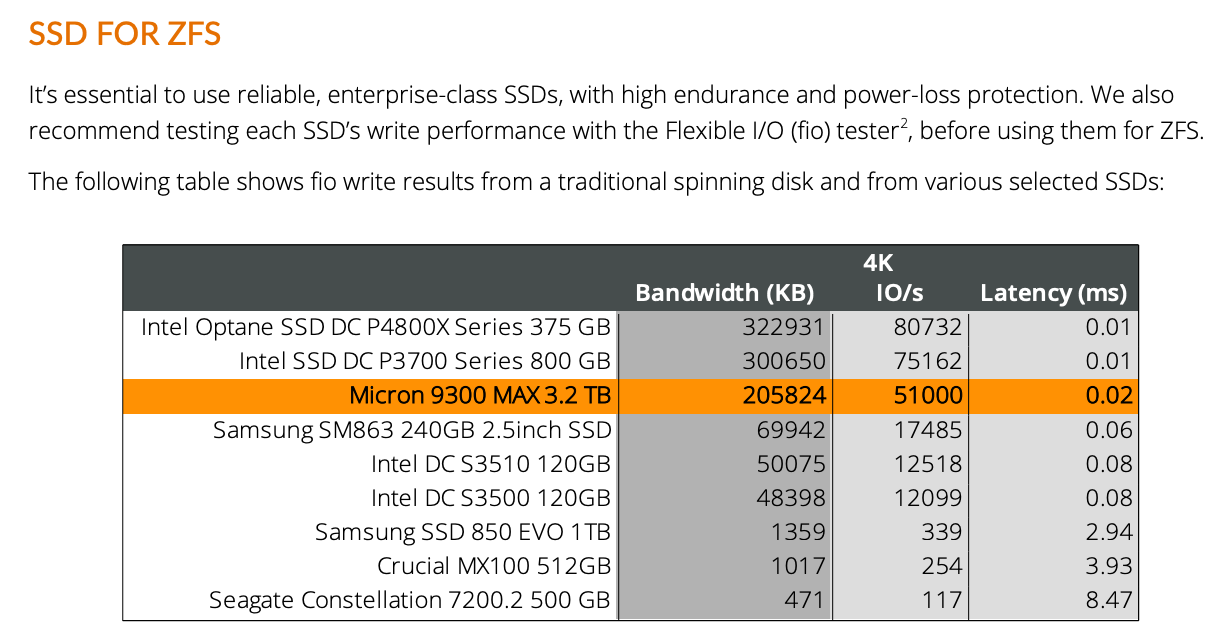

但是这里的测试结果实际上跟ZFS无关。这个FIO command 测试的是直写性能,而且似乎也不是random的,但是确实是sync+4K。所以参考价值还是很高的。可惜的是,这个文档并没有测试Samsung 850这类consumer SSD在ZFS上面的表现。我们穷人还是不知道consumer SSD在ZFS上面,一个合理的performance expectation大体是个什么程度。当然从这个结果我们已经可以看到消费级(Samsung 850)和企业级的巨大差别(Intel DC S3500)了。
测试环境 | Setup
主机系统是Proxmox 7.4,CPU是i5 7600k,RAM:64GB,其中16GB给到了TrueNAS Scale虚拟机。主板是历久弥新的Gigabyte z270p。虽然是旧平台了,但是老平台接口全啊(3个PCIEx16物理插槽,3个PCIEx1物理插槽,可惜只有一个NVME,最大也只有64GB内存)。
zfs version:
- zfs-2.1.6-pve1
- zfs-kmod-2.1.6-pve1
TrueNAS VM直通了一个SATA expansion card,上面接了一个Seagate EXOS 14TB和一个 WD EDGZ 白标拆机 14TB,两个应该都可以算是企业级HDD,组成ZFS Mirror。TrueNAS VM只给了2个CPU Core。
- Version: TrueNAS-SCALE-22.12.0
- ARC max size: <8GB (by default arc is 50% of the system memory for TrueNAS Scale as it is on Linux)
另外手上可以用来测试的SSD:
- Crucial M500 480GB。一个相当早的SSD了,但是这种早期的SSD是被ZFS认为带有Power Lost Protection (PLP)的(详见这里)。所以给ZFS用还有可能是比现在的SSD更好的选择。
- Crucial MX500 512GB。一个现在被认为在SATA SSD品类里面不会错的选择。作为消费级标杆(i.e. 比上不足比下有余)非常合适。
- ADATA LEGEND 850 2TB PCIE 4.0 NVME。一个PCIE 4.0中速NVME。对于NVME,受限于主板的pcie 3.0 m.2接口,我们这里只做大体上定性的分析,具体说数值很可能不是很有参考性。
这里有几个地方肯定是犯了众怒的,但是有限于条件,只能将就了。
- Memory不是ECC。不过这个应该不影响性能。
- 两个HDD是接在SATA Expansion card上面,而不是正经HBA card。而且SATA expansion card还是接在pcie 3.0 x1的接口上。此处的安排并不推荐。但是个人用下来目前没有什么问题。pcie 3.0 x1的接口速度对于两个HDD来讲还是够的,大体上到4块HDD的时候才有一点点可能出问题。
- TrueNAS是VM。依旧不推荐这个安排,但是对于家用以及小作坊,个人认为也是可以的。只要确保硬盘是通过PCI控制器直通进TrueNAS就行。而且仅限于偏向AIO的架构方案,如果要严肃一点的话,VM和Data还是物理上分离为好,或者彻底做HCI方案亦可。
测试会偏向于4K的测试,因为之前在使用这两个SATA SSD作为VM的storage时,观察到性能非常令人失望,所以才有的这个测试。具体就是要看看小文件写入上面的区别。
测试会采用如下命令
fio --filename=test --sync=1 --rw=randwrite --bs=4k \
--numjobs=1 --iodepth=<qd> --group_reporting \
--name=test --filesize=10G --runtime=<time>qd: 1, 16, 32time: 300 seconds or 60 seconds 主要是300太长了,等不及了。
测试会对比一下,2个HDD组成ZFS mirror的情况,然后看看2个sata SDD组成 ZFS mirror的情况,相比HDD孰优孰劣。之后看看NVME能有多大的提高。因为手上只有一个NVME,主板上也只有一个m.2接口,所以NVME就没有办法mirror了。
NVME的单盘ZFS性能测试和HDD ZFS Mirror是在TrueNAS之下做的。而M500+MX500的 ZFS mirror是在Proxmox下面做的。测试时NVME里面大概有100G的数据,HDD里面有1TB数据,M500/MX500里面有300G数据(这个比例对于480G的总空间来讲算是比较多的了)
而后NVME被从TrueNAS中取出(实际上是NVME的Controller直通被取消),然后在Proxmox上面组LVM Thin,用来支持LXC。之后创建了一个Ubuntu 22.04的LXC,分配592GB的空间,在这个LXC里面运行fio进行写入测试。
测试与结果 | Tests and Results
除非特殊说明,测试都采用 job=1的参数,所以测试结果并不是这个硬盘的最大性能。应该说,目的就不是最大性能,而是看看对于单纯的一个写入磁盘的操作,性能差别能有多大。(而且我总是怀疑这个job和queue depth是不是有重叠。)
4K同步写入测试
| 4K SYNC RANDWRITE - AVG IOPS | QD1 | QD16 | QD32 |
|---|---|---|---|
| NVME 1-disk ZFS noatime | 2,058 | 2,096 | 2,057 |
| HDD 2-disk ZFS Mirror noatime | 84 | 96 | 62 |
| M500/MX500 2-disk ZFS Mirror noatime | 65 | 45 | 46 |
| NVME LVM-Thin 592G First time | 1,072 | - | - |
| NVME LVM-Thin 592G Second time | 1,726 | - | - |
| NVME LVM-Thin 592G - noatime first time | 2,139 | - | - |
| NVME LVM-Thin 592G - noatime second time | 2,628 | - | 2,702 |
若不是亲眼所见,真的很难相信M500+MX500的性能可以差到这个程度。这个羸弱的IOPS性能导致在其上运行的任何VM都会比蜗牛还慢。没有想到的是,这个成绩比HDD都要慢,就算是SSD空间占用有点多了,也未曾想到可以差到这个程度。可能是磁盘本身的fragmentation程度已经比较差了。不过后续的测试告诉我们可能不是这样的。
HDD的性能可以说比较符合预期,磁头的寻址延迟差不多在1ms左右,对应的IOPS就很难超过100。
NMVE的性能无论是ZFS还是LVM thin都算是能用的。我们之前链接中给出的Proxmox的企业级NVME测试结果中,Single Job下的randwrite成绩在2325。可以说我们获得的这个NVME的性能是符合预期的。(至于job=4, job=32的情况,本次没有测试)。
对于NVME+LVM thin,结果有些奇怪。因为LVM thin有 lazy alloc的特性,所以很可能每次跑的成绩有较大浮动。毕竟我们没有什么好办法控制其空间的回收和分配。比较值得注意的是,对于LXC上面,storage mount选项中noatime。这个选项能够很大的印象sync write的性能。这一点具体的原因我还不是很清楚,因为我理解noatime应该是对于读写的情况影响比较大,但是单独的写入不应该有这个问题才对。也可能是我理解不到位。
值得注意的还有测试过程中的波动性,也就是性能的稳定性
| 4K SYNC RANDWRITE - STDEV | QD1 | QD16 | QD32 |
|---|---|---|---|
| NVME 1-disk ZFS noatime | 242 | 274 | 1,331 |
| HDD 2-disk ZFS Mirror noatime | 42 | 33 | 46 |
| M500/MX500 2-disk ZFS Mirror noatime | 257 | 44 | 48 |
| NVME LVM-Thin 592G First time | 83 | - | - |
| NVME LVM-Thin 592G Second time | 856 | - | - |
| NVME LVM-Thin 592G - noatime first time | 811 | - | - |
| NVME LVM-Thin 592G - noatime second time | 305 | - | 274 |
从上表可以看出,NVME 1-disk ZFS的稳定性还是不错的,只有QD32多情况下偏高。而HDD的ZFS Mirror相比之下差了很多,反应了磁盘寻址latency的随机性。此处别忘了对比离散程度还要对照各自的mean值。而2-disk ZFS mirror在QD1的这次测试中非常不稳定。后面QD16,QD32表现也很一般,毕竟基础的mean的很低了。实际测试是最低的IOPS可以低到2,简直匪夷所思。NVME在LVM-thin中的表现也很不稳定,可能也是反映了lazy alloc的特性。综合来看,NVME的稳定性好很多。
4K异步写入测试
| 4K ASYNC RANDWRITE - AVG | QD1 | QD16 | QD32 |
|---|---|---|---|
| NVME 1-disk ZFS noatime | 8,959 | 9,678 | 14,652 |
| HDD 2-disk ZFS Mirror noatime | 3,790 | 2,403 | 6,495 |
| M500/MX500 2-disk ZFS Mirror noatime | 399 | 639 | 885 |
| NVME LVM-Thin 592G - noatime first time | 122,223 | - | - |
| NVME LVM-Thin 592G - noatime second time | 205,531 | 179,362 | 212,291 |
sync=0 之后,各方的数据都有很大的提高,分析如下。
NVME ZFS single disk的性能和NVME LVM-thin开始拉开差距。LVM-thin的性能开始接近NVME厂家宣称的数量级,即数百KIOPS的量级,但是ZFS方面则最多在10K这个量级。但是当时测试时发现TrueNAS(也就是NVME+ZFS的测试)的CPU占用达到80%以上,有可能CPU是瓶颈,所以这个数据结果只能作为参考,很可能不具有实际意义。当然,至少这个性能对于家用或者小作坊,已经很可用了。另外我这里jobs定为1,这个数值增大的话,还是很可能可以极大的提高此处的成绩的。
HDD ZFS Mirror的提升非常明显。这也是为什么ZFS比较推荐用Optane组ZIL的原因,因为如果Sync write性能可以因为ZIL的存在,等同于async write,那么通过阵列组合,HDD也可以获得非常不错的性能。比如24盘位,组4个6盘RAIDZ2。假设磁盘性能好一点(比如EXOS 14TB实际上单盘可以到达8KIOPS的async 4K写入),那么阵列就可以达到32KIOP的性能。这个性能相比于很多SATA SSD 4k sync write性能,已经非常好了,甚至已经超过了一般双SATA SSD RAID0(参考之前提到的Proxmox的测试结果,Intel DC S3510 120GB的4k直写性能是12K)。而想要HDD达到这个效果,需要的只是两个小容量的Optane P950。
很显然,ZFS确实对于大量HDD组RAID的场景有相当好的支持,甚至是硬盘越多,得益越多。从另一个角度想,确实如此,假设有无穷的资源供给无穷可靠性的RAID卡,那么自然是硬盘越多,性能越强。如果有Optane,自然是要用在Sync write上面。而ZFS就是把这一套方案打包,同时用ECC内存和一些CPU开销tradeoff硬件阵列卡。很大程度上是依赖CPU和内存的可靠性。应该说在现在这个技术路线下,是非常合理优秀的取舍。
最后回来看consumer SDD ZFS mirror的表现。可以说是匪夷所思了。如此之差的表现比之HDD mirror差了很多。可以说在这里已经完全没有任何使用这个SSD Pool的必要了。这跟我之前在这个Pool上面跑VM的情况一样,完全不如直接使用HDD的pool来的稳定可靠。使用这个SSD pool时,Proxmox的IO delay经常起飞,如果Proxmox OS 也在这两个SSD上面的话,Proxmox会被整体带崩,无法访问。
为了探寻一下MX500和M500里面究竟是谁造成的这个结果,我又单独测试了两个SSD一次。不过这两次测试时,两个磁盘已经清空了,自然不会受到 fragmentation的影响。
单MX500 ZFS 性能
| Test case | min | max | avg | stdev | samples |
|---|---|---|---|---|---|
| mx500 direct, 4k, sync, QD 1, libaio | 1,946 | 2,528 | 2,154 | 108 | 119 |
| mx500 single zfs, 4k, sync, QD 1 | 1,072 | 1,820 | 1,618 | 180 | 119 |
| mx500 single zfs, 4k, sync ,job 1, QD 1, atime=off | 970 | 1,818 | 1,597 | 180 | 119 |
| mx500 single zfs, 4k, async ,job 1, QD 1, atime=off | 9,256 | 34,254 | 25,154 | 5,182 | 119 |
第一个测试是使用Proxmox benchmark里面提供的直写测试命令得出的。可以看到性能跟Samsung 850之类的是在一个数量级的,可以算是很接近的。
4K的同步写入性能也还是比较正常的,比NVME差,但是确实差距不跨数量级。另外,noatime与否,对性能并没有什么影响。
4K异步随机写入性能好了很多,开始能够达到标称的性能数量级。如果jobs的数量上去的话,大概是能达到宣称的数值(标称应该在90KIOPS)。不过我们要知道,这里肯定有DRAM的作用。受限于时间,就没有再多做测试了。
单M500 ZFS性能
| test case | min | max | avg | stdev | samples |
|---|---|---|---|---|---|
| m500 direct, 4k, sync, QD 1, libaio | 38 | 234 | 196 | 64 | 119 |
| m500 single zfs, 4k, sync, QD 1 | 6 | 222 | 178 | 63 | 119 |
| m500 single zfs, 4k, sync, QD 1, atime=off | 28 | 220 | 177 | 58 | 119 |
| m500 single zfs, 4k, async, QD 1, atime=off | 1,448 | 41,262 | 9,087 | 10,872 | 118 |
整体来讲比MX500差了很多。应该说Consumer SATA SSD在2010-2020这期间还是有进步的吧。我手里的M500和MX500应该都是512MB的DDR3缓存。容量上480GB vs. 512GB,差别并不大。但是在ZFS的性能上的差距很明显。
从结果看,似乎是M500拖了后腿,但是确实M500单盘的性能还是比mirror的表现好,这其中的玄妙目前就很难说清了。可能是因为两个SSD的主控差距太大,放在一起,互相之间反而不兼容?
结论 | Conclusion
- M500 + MX500组合出来的ZFS完全不可用。可能采用不同时代的SSD组ZFS pool,并不是一个好的选择。而如果采用两个完全一样的SSD,也许结果会很不一样。
- ZFS在企业级的HDD上面,4k随机写入,表现合理,甚至可以说是优秀。
- ZFS单盘NVME对NVME的性能可能还是有影响,可能异步写入的性能会导致CPU负载升高。某种程度上反应了目前NVME的性能,导致CPU<>IO之间的性能鸿沟被大大缩小了。以往coding的时候把IO操作当作“Infinite“的逻辑似乎已经不成立了。
- LVM-thin也是有些性能开销的,如果追求 consistent performance,那LVM-thin + NVME恐怕不是一个好的选择。至于lazy alloc会导致这么大的影响,似乎也可能是因为现在NVME的性能确实大大超过了过去人们的预估。
最终在这个实验结果的指导下,MX500和M500被我拆开,跟更古早的2.5寸笔记本hdd组boot pool去了。毕竟boot drive上面不跑VM,基本上是负载最低的地方了。而VM改成用NVME来跑。VM本身实际上是偏 Ephemeral 的东西,所以哪天如果真的挂了,换个盘从backup上面恢复,或者直接重新create就好了。HDD依旧给TrueNAS做data pool,存 persistent data。
这个测试以及结论还非常不严谨,欢迎各位读者留言讨论。
参考资料 | References
在之前的各种无尽的调试(折磨)中参考了以下资料: