Create the ZVOL in TrueNAS
- /mnt/tank/vm-disks/pbs
- compression: off
- Why? 因为 PBS 已经进行了 lz4 压缩。
- volblocksize: 128k
- Why? this is the default recordsize when using zfs on PBS data disk
- sparse: true
- We start with 8TiB (a big chunk), so sparse is good.
- disable secondary cache
secondarycache=none, this needs to be done via shell
- compression: off
NOTE
This is a zvol specific for PBS. The compression and volblocksize is NOT ideal for general VMs (64k for general Linux, 16k or 32k for Windows)
Create the iSCSI share
iscsi wizard:
- name: truenas-pbs
- extent type: device
- device: tank/vm-disks/pbs
- sharing platform: Modern OS
- WHY? I don’t know, but I’m not using VMWare nor Xen. And Proxmox 9 is pretty modern.
- portal: create new, or reuse the same IP and 3260 port.
- ip address (the listening ip): 0.0.0.0
- initiator: keep it empty
- Why? 这个实际上要的是 iqn,不是 ip或者cidr。留空就是 allow all initiator,这样我们之后在PVE上面才能找到这个target。等连上之后,可以再回来把initiator加上
TIP
PVE 的 iqn 存在: /etc/iscsi/initiatorname.iscsi 所以其实就算你重装 pve,只要一直备份这个iqn,就可以让 iscsi 挂载在重装后还能无痛衔接。
然后其实无论怎样,是否需要migration,还是比较建议备份一下这个 initiator name 的。
Add iscsi storage in PVE
If you keep the ‘use LUNs directly’ flag set:
- The iSCSI share will only be usable for one VM.
- If yo leave the flag ‘unset’, you will be able to create lvm-thin on top of the LUN in PVE and shared it with multpile VMs (and even across your PVE cluster if you use multiple nodes in our PVE cluster)
我这里选择了打开。这个 LUN 就是专门给 PBS 用的。之前的 zvol 的参数都不适合其他的 VM。
PBS VM
首先还是先用个32GB的系统盘装上 PBS,然后关机再搞 data store 的事情。
Add storage disk
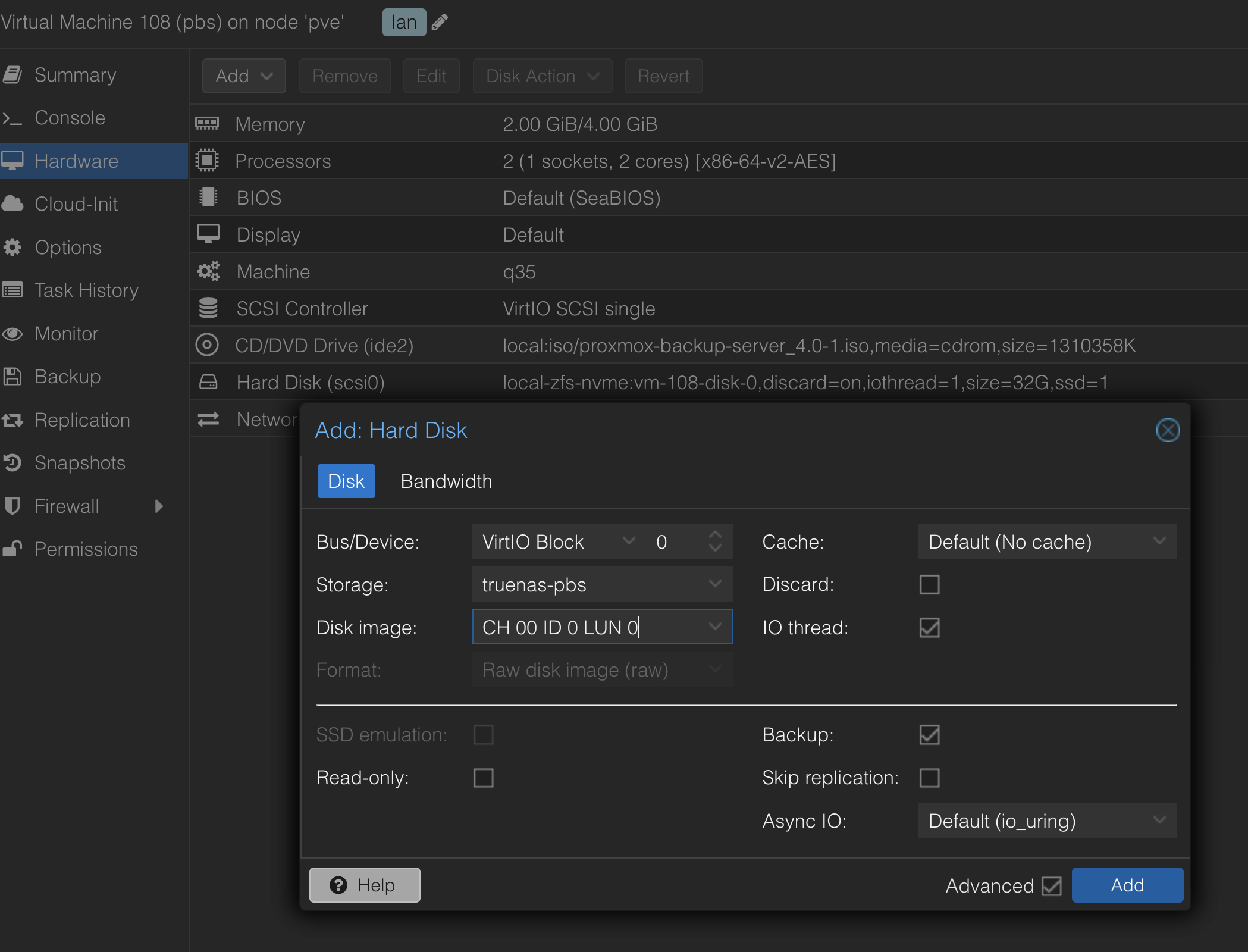
- 这一步似乎扫描起来比较慢。
- 另外,这个地方用 virtio block 性能可能会更好一些。
In the VM:
- create ZFS with the /dev/vda.
- The default recordsize is 128k, aligned with our volblocksize=128k.
- Also, zvol should have the compression disabled.
- Assuem the name of your zfs pool is
truenas-pbs-pool
zfs set atime=off truenas-pbs-poolzfs set xattr=sa truenas-pbs-pool
Use community post install script: https://community-scripts.github.io/ProxmoxVE/scripts?id=post-pbs-install
- Fix the repository for community users.
- Drop the nag of ‘subscription’.
Then, install the ‘qemu-guest-agent’.
PVE setup
Get the user name, password, datastore name and the fingerprint from PBS
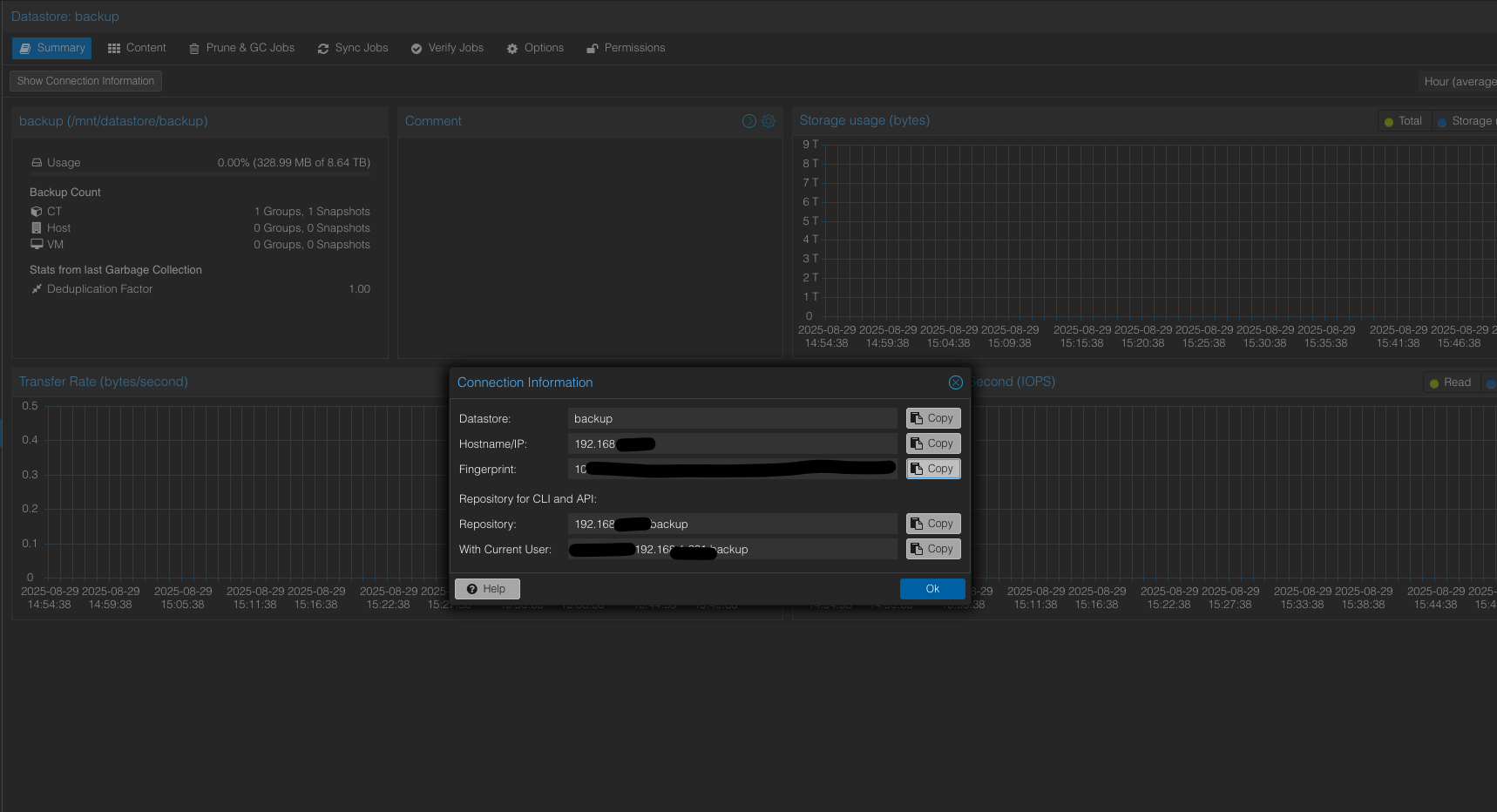
- user name: you can typically use root@pam
- copy the fingerprint from the conneciton information.
这个过程中还产生了挺多讨论的:
- 为什么不直接在 TrueNAS 里面创建虚拟机跑 PBS?
- 网上实在是找不到 nested virtualization 的实用案例。
- TrueNAS 上面对于 VM 的恢复,操作可能不方便,毕竟 TrueNAS 不是个 HyperV 平台。
- Gemini 无论怎么样都不推荐这么做。
- 为什么不用 PBS LXC?
- 这个方案的好处的限制都在于:使用PVE本地 Storage Directory。
- 如果住 Pool 在 PVE 上面,这样挺好。如果不在,像我现在是在 TrueNAS 上面,就反而不方便。
- 我个人还是害怕未来 PVE 升级的时候把 kernel 搞坏了,然后又突然启动不起来了。
- 为什么在 VM 里面不用 EXT4?
- 如果是 EXT4, 那下层的 zvol 应该用 volblocksize=64k, 然后打开 compression。
- 为什么不用? 其实理由不太充分。可能想着以后还能在 PBS 里面用 zfs send,以后迁移可能方便一些。
- 为什么用 iscsi 而不是 nfs?
- PBS 的小文件读取数量可能有点多,可能不太适合用 NFS 这种协议。NFS的网路开销可能还要比 iscsi 高。
- 如果是 NFS 那估计就不搞 zvol 了,直接data set 就可以了。
- 其实真的不应该在这个上头花这么多时间的。
- 严肃一点的 backup 其实还是只能考虑 “另一个单独的 machine”。
- 所以可能还是应该直接在 TrueNAS 里面起一个 PBS VM。能用就用,不能用的话随时抛弃。
- 现在这个配置实在是有点麻烦:
- TrueNAS 上面需要针对 zvol 进行特殊设定。然后需要给出来 ISCSI
- 然后 PVE 需要 mount,但是 PVE 还不能用。只能直接direct给 pbs VM.
- 然后 pbs 上面还需要搞 ZFS,又需要一些 zfs settings。
- 现在这个配置实在是有点麻烦:
- 还有一个可能更合适的方案:
- 用 LXC,然后 bind mount 或者用 UI 里面的 mount point
Gemini summary:
最终建议的优先级:
最佳方案 (Best): PBS on VM + iSCSI。性能最高、最稳健、官方支持。这是“正确”的工程方案。
次优方案 (Second Best): PBS on LXC (整个容器都在 NFS 上,即 .raw 模式)。这是在坚持使用 LXC 的前提下,性能最好的选择。它用一个额外的文件系统层,换取了对 NFS 更友好的 I/O 模式。
最差方案 (Worst): PBS on LXC (系统盘在本地, 数据盘绑定挂载 NFS)。这是最直接,但性能可能最差的方案,因为它将 PBS 的元数据密集型负载,直接暴露给了 NFS 的性能弱点。
这里比较有意思是是, 如果是 mount point 就会在 nfs dir 里面创建一个 .raw 文件。如果是 bind mount,自然就直接能看到 pbs data store 的文件了。 然而,.raw 的大文件,实际上可能速度更快。关键可能就是,PBS 的 data store 里面元数据比较多,有点像数据库,所以 nfs 的网络开销就很大了。
From Gemini:
工作原理: 这个方案巧妙地在 PBS 和 NFS 之间,增加了一个本地的、高效的“缓冲区”——ext4 文件系统。
优势:
PBS 所有密集的元数据操作,都发生在容器内部的 ext4 文件系统上。ext4 是一个极其成熟和高效的本地文件系统,处理这些操作的速度飞快。
ext4 文件系统将这些复杂的操作,最终转化成对底层 .raw 文件的、更简单、更连续的**“块写入”**操作。
最终,NFS 协议不再需要处理那成千上万次的“文件查询”,而只需要处理对一个巨大文件的“块写入”请求。这极大地降低了 NFS 的元数据开销。
比喻: 这就像您在车间里,先将所有小零件都整齐地码放到一个标准化的集装箱 (.raw 文件)里,由一位经验丰富的本地仓管 (ext4) 来负责整理。整理完毕后,您只需要让快递员 (NFS) 一次性地将这一个集装箱运送到远程仓库 (TrueNAS)。物流效率大大提升。
- 测试,关闭 pbs, 断开 datastore 的 disk,然后开机 → in PBS, datastore NAN 报错。
- 关机,重新连上 data store 的 disk。开机,恢复了。
- 确认了 pbs 上面 data store (ZFS) 确实没有用到 /etc/fstab.
另外一个问题,因为无论是 zfs command 本身,还是 TrueNAS,都只能在一个 zfs send/recv or replicate job 里面支持一个 source. 然后我又不想单独再给 cold-backup 搞一个 script 用。所以最后还是决定,要把 critical data 的 dataset 都移动到一个 critical/ 的 dataset 里面。 然后无论是冷备份还是远程,都选择直接备份这个 critical dataset.
Details in : [move-all-critical-dataset-to-a-new-parent-dataset-to-make-backup-easier]
Appendix
PBS 本身的 system disk backup:
- target: TrueNAS backed NFS.
- Make sure I disabled the ‘backup’ for the data store disk.
- 灾备:
- pbs boot: TrueNAS tank pool, the nfs dataset, then will be backed up to the cold backup disk.
- pbs data: TrueNAS tank pool, the pbs zvol dataset (iscsi share), then will be backed up to the cold backup disk.
TrueNAS 本身的 backup:
- target: create a new ‘dir’ type storage based on the ‘local-staging’ zfs (by default it will be mount to /local-staging/ dir, so I can directly use that dir as a ‘dir’ type storage.)
- 灾备:
- export the config, and store it to Google Drive.
TrueNAS cold backup:
- 这里其实就是 TrueNAS 擅长的地方了。 (UI for snapshot, replication, auto incremental replication, etc)
- 首先是创建 ‘cold4’ pool.
- recordsize=1m; secondarycache=none; primarycache=metadata; atime=off
- sync 还是要保持为 standard 的。
- 然后可以创建 replicate job
- source: tank/critical/backups, tank/critical/shared
- target: cold4/truenas-tank/critical/
- one-time job.